Artificial intelligence in law and legal practice
Artificial intelligence (AI) is changing the practice of law. Legal AI tools can help lawyers automate manual processes and work more efficiently, but as AI technology continues to evolve, legal professionals need to understand how to balance the benefits with the potential risks and ethical questions of AI in law and legal practice.
The AI innovations you need to stay ahead
For more than a decade, Bloomberg Law has been perfecting the power of artificial intelligence to help lawyers speed up and simplify legal tasks. With recent AI and machine learning breakthroughs, now even more is possible.
Pinpoint the best case law in seconds
Stop sifting through irrelevant opinions. Our AI-powered case law research tools help you easily find the leading case law, guiding legal principles, and best language to support your argument.
Write a better legal brief in less time
Leverage machine learning capabilities to automate tedious brief analysis steps. With Brief Analyzer, review a legal brief in seconds, check citations, and find suggestions to improve your draft or response.
Be better prepared for litigation
Cut through millions of data points to visualize trends, predict case outcomes, advise clients, and develop an informed strategy with insights about courts, companies, and your competition.
Legal professionals are harnessing artificial intelligence to help them meet new and ongoing challenges. For example: AI can help lawyers quickly produce initial drafts of motions, legal briefs, contracts, and settlement agreements, which in the past have been time intensive.
However, the use of AI in law also raises issues of algorithmic bias (when the algorithm itself is biased, or when an otherwise unbiased algorithm is trained on biased data), hallucinations (the phenomenon by which AI chatbots may provide false information in response to a prompt), inaccuracies, and confidentiality concerns.
Here, we take a comprehensive look at AI for lawyers and available AI functionality within legal software, while also examining the potential risks of AI solutions and technology’s role in the future of law. Read on to learn more about the impact of AI in the legal profession, and discover how lawyers can strategically and ethically use this technology to automate and simplify legal tasks.
[Download A Buyer’s Guide to Legal AI Tools for expert tips to help legal professionals choose the right AI solutions to enhance their practice.]
What is artificial intelligence?
Artificial intelligence is an umbrella description for technologies that use computers and software to emulate intelligent, humanlike processes.
What is generative AI?
A generative AI tool generates “output,” typically in response to instructions, called the “input” or “prompt,” from a user. The output is based on an algorithmic model trained on vast amounts of data, which could be text, images, music, computer code, or virtually any other type of content.
What makes generative AI different from more familiar algorithm-based machine learning technology is that it draws on enormous data sources to instantaneously create seemingly new, task-appropriate content such as essays, blog posts, poetry, designs, images, videos, and software code. With the release in late 2022 of ChatGPT, a sophisticated chatbot from AI research nonprofit OpenAI, more attention has turned to generative AI and large language models.
How is machine learning different from artificial intelligence?
In the legal context, computers and software frequently employ AI in the form of machine learning (ML) that facilitates the automation of legal work and improves its performance of specific tasks over time.
There are three types of machine learning:
- Supervised machine learning: a subset of AI in which the application seeks and recognizes patterns within predefined data sets. These data sets are typically created by human domain experts who act as guidance counselors of sorts to the machines.
- Unsupervised machine learning: a type of ML that creates data sets without known outputs or predefined data. In this type of application, there isn’t an expert-created data set guiding the tool’s behavior. The software, in essence, learns and adapts to the inputs on its own.
- Reinforcement learning: a type of ML that “rewards” the application to create correlations using an algorithm that incorporates data feedback and learns from it to uncover the ultimate processing path.
What is AI in law?
Legal AI software helps legal teams save time by finding legal information in seconds. This kind of tech is valuable because it can pore over massive amounts of data. Specifically, a major benefit of AI for legal research is that these tools allow attorneys to gather insights from large sets of data and focus solely on the legal information that matters most, enabling them to be more efficient and more strategic, and offer more value to their business or clients.
Legal AI can also help busy legal teams with contract drafting and analysis, case strategy, legal project management, and motion drafting.
What is agentic AI for law?
Agentic AI for law can be described as a set of software “helpers” that can understand instructions, break the work into steps, use different data sources and tools, and work together to complete legal tasks from start to finish. The agents can also adjust based on lawyer feedback
Agentic AI can help lawyers and legal teams with many everyday tasks, like doing legal research, drafting contracts, and supporting business development. For example, agentic AI may be used to pull together a company’s litigation history into an easy-to-read profile that shows past cases, outcomes, and patterns to support client pitches.
Which AI is best for law?
The best AI tools for law are designed specifically for the legal field and built on transparent, traceable, and verifiable legal data.
Because lawyers work in a field that places utmost importance on accuracy, professionals in this space should be cautious about relying on tools that employ purely unsupervised learning techniques. To avoid the risk of inaccuracies or missing documents, the best AI for legal professionals utilizes supervised machine learning tools.
The value in AI is the ability to analyze massive amounts of data and unearth details that are undetectable to the human eye. Yet without human expertise ensuring the quality and accuracy of that data, AI can do more harm than good.
Bloomberg Law has an extensive benchmarking process and user acceptance standards for our generative AI tools. With the help of former attorneys, we evaluate the accuracy of our generative AI throughout the life of the product. With these guardrails in place, we’re able to continuously tune the model to prevent it from drifting over time or answers becoming less accurate.
How is AI being used in the legal profession?
Some professionals in the legal industry have been deploying AI for the better part of a decade to parse data and query documents. However, the explosion of interest in powerful tools like ChatGPT has encouraged more legal professionals to experiment with the technology on the job. This rapid shift has led a growing number of law firms and in-house legal departments to establish guidelines for using AI solutions in order to responsibly harness the technology in the workplace.
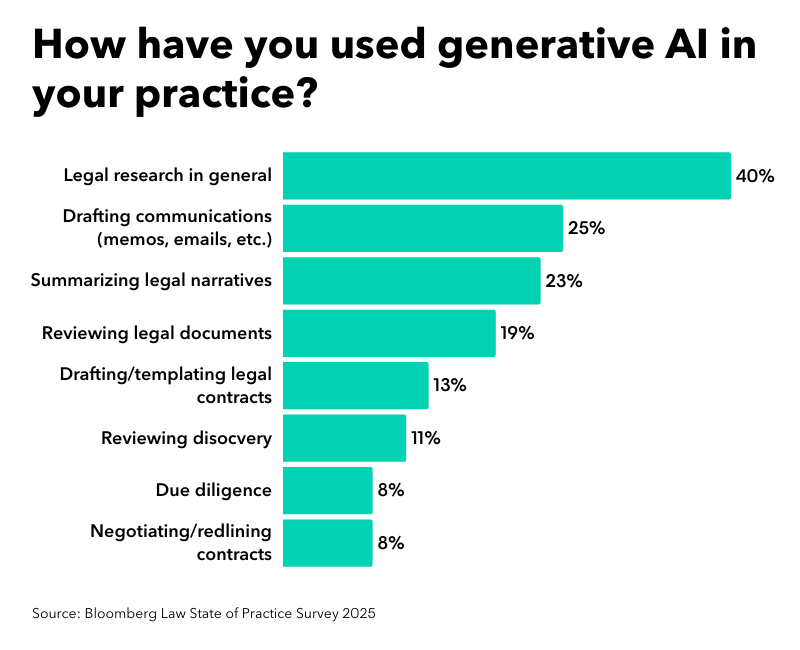
In our 2025 State of Practice survey, we asked legal professionals at law firms and in-house departments about how they have used generative AI in their practice.
Top 6 ways lawyers are using AI
The main ways that legal professionals are using generative AI in their practice are:
- Conducting legal research
- Drafting communications (memos, emails, etc.)
- Summarizing legal narratives
- Reviewing legal documents
- Drafting/templating legal contracts
- Reviewing discovery
What are examples of AI tools lawyers use?
Today, legal professionals are turning to a wide variety of AI solutions to support their everyday tasks, from project and case management to drafting briefs and contracts.
General AI tools used by lawyers include:
- ChatGPT
- Anthropic’s Claude AI
- Gemini (a Google product)
- Copilot by Microsoft
All three AI solutions offer a basic, free version of the software and can operate as a virtual AI assistant. However, some of these general AI tools may not offer the sufficient guardrails required for all functions in the legal field, where accuracy is paramount. Furthermore, these tools may not account for rapid developments in the legal space, or provide attorneys with the peace of mind that they are sourcing the most current information on a given topic.
Bloomberg Law’s trusted, tested AI for lawyers is built on a foundation of comprehensive primary and secondary sources, up-to-the-minute news coverage, expert attorney-written analyses, and top-tier business intelligence.
Bloomberg Law’s AI Assistant can fast-track research for legal professionals. With the AI Assistant, lawyers can confidently delegate routine, time-consuming tasks – like searching, summarizing, and comparing legal content – and spend more time on the work that truly matters.
[Download A Buyer’s Guide to Legal AI Tools for expert tips to help legal professionals choose the right AI solutions to enhance their practice.]
AI for legal research
One of the most common ways legal professionals use generative AI in their practice is in legal research. Older technologies such as natural language processing and machine learning can extract insights and connections from vast databases of court opinions and dockets to improve the speed and comprehensiveness of case law research.
Within Bloomberg Law’s market-leading docket search feature, we use machine learning to make it easy to narrow searches to exactly the types of pleadings, motions, and briefs you need. The algorithm helps surface the filings users are looking for, not those that merely mention the keyword.
Generative AI for legal research can summarize and condense a large volume of documents to help lawyers quickly understand key themes and points.
For example, Bloomberg Law Answers generates a response or summary to your question or keyword utilizing primary and secondary source documents. The feature also provides citations and links to supporting authorities and source documents that were used when generating the answer.
Likewise, our AI Assistant is a chat-based efficiency and discovery tool, allowing users to complete their research faster and discover resources and tools on the Bloomberg Law platform to facilitate their legal work.
AI for legal document review
There also are legal AI tools that can specifically help with transactional law. Many attorneys are using AI for faster and more consistent review of legal contracts. For example, Bloomberg Law’s Draft Analyzer uses AI to identify how contract language may deviate from the market standard and help attorneys more quickly determine what language their counterparty usually agrees to.
With generative AI tools for contract drafting, like Bloomberg Law’s Clause Advisor, attorneys can immediately evaluate clause favorability and easily modify the language in favor of one party with a user-friendly slider tool.
AI for e-Discovery
The e-Discovery process is often taxing for legal professionals due to the amount of electronically stored information (ESI) that legal teams must sort through. AI-powered e-Discovery software can streamline the process and help legal professionals more efficiently identify relevant ESI using capabilities such as advanced algorithms, machine learning applications, process automation, and text analytics.
This sort of AI for lawyers can save valuable time and allow legal teams to instead focus on more strategic tasks. Ultimately, law firms and in-house counsel can increase their productivity, cut labor costs, and change the value proposition for delivering legal services to their clients and stakeholders.
What are the ethical risks of using AI in legal work?
With the availability of various AI-powered tools, lawyers may feel tempted to jump right in and try a few. But before taking the leap, it’s crucial to understand the risks surrounding the use of AI in the legal profession – and the laws and regulations already being put in place to address them.
The top areas of ethical concern about AI are:
- Deep fakes (e.g., human impersonations)
- Hallucinations and accuracy of AI-generated text
- Data and privacy
- Model bias
- Intellectual property
- Job security
With these ethical concerns and other issues in mind, today’s lawyers must balance the efficiencies of generative AI with compliance to ensure the use of legal AI software is compatible with their professional ethical obligations.
Industry guidance on the ethical use of artificial intelligence
The American Bar Association (ABA) Model Rules of Professional Conduct note that it’s a lawyer’s duty to ensure any nonlawyer’s conduct aligns with those of the supervising lawyer. Notably, the work of AI – and its resulting outputs – would be subject to this rule.
As of 2025, there are 16 state bars that have addressed or are planning on addressing AI and legal ethics. All nine of the ethics opinions issued so far discuss lawyers’ supervisory duties related to generative AI use. While they all reference the more obvious ethical obligation to oversee nonlawyer staff’s use of Gen AI, several also discuss supervisory duties related to generative AI itself.
For instance, a Florida bar ethics opinion from 2024 advises lawyers to review the work product of generative AI tools similarly to how they would a paralegal and also ensure that work delegated to generative AI doesn’t ethically require the personal judgment of a lawyer.
How artificial intelligence is transforming the legal profession
AI has the potential to transform the legal industry as a whole – from law firms and in-house counsel to legal operations and even law schools.
The emergence of generative AI points to a future where AI may be embedded into multiple levels of an attorney’s work. AI will augment the work that individual attorneys do, and it will likely become woven into the fabric of daily tasks. We are already seeing this change, for example, in the integration of AI as a copilot across common productivity programs, such as word processing, timekeeping, and communication platforms.
AI will also transform the delivery of legal services at the practice level. Law practices that conduct similar types of legal work repeatedly will be transformed by AI automation and augmentation at scale. The inefficiencies and redundancies at the core of these tasks will be radically optimized through AI – from devising legal strategies to reviewing evidence and drafting briefs – enabling attorneys to focus on the strategic work that’s best suited to their roles. This change will create opportunities to scale – or increase revenue at a faster rate than cost – that didn’t exist before.
In addition, AI will affect the study of law. While some professors have shared concerns that AI for law students encourages cheating, many law schools and professors proactively incorporate AI ethics into the classroom. For instance, some professors allow or even require students to experiment with generative AI tools like ChatGPT, but typically note that blame will fall on the student if the technology outputs incorrect information the student doesn’t rectify.
Given the ongoing impact of AI on the legal profession, educators understand that aspiring lawyers need to be fluent in AI and understand how it can and cannot be used in the practice of law.
Can AI replace paralegals?
There is potential for AI to impact certain duties performed by legal assistants, paralegals, and even early-career attorneys. However, it’s important to remember the use of AI must be compatible with the rules of ethical conduct that lawyers abide by.
For instance, the ABA Model Rules specifies law firms’ and associations’ responsibilities regarding legal assistants. The rule notes that it’s a lawyer’s responsibility to ensure any nonlawyer’s conduct aligns with those of the supervising lawyer. Notably, the work of AI would be subject to this rule.
Lawyers also have a duty to train and supervise nonlawyers who assist them, and this duty also applies to AI assistance. If generative AI doesn’t understand, for example, the legal nuances in a particular jurisdiction, or if it includes other errors, the supervising lawyer is responsible for any mistakes it might make.
So, rather than replacing jobs like those of paralegals, it’s more likely that AI will help legal teams – especially in-house legal departments – to retain more work in-house. This will, in turn, allow these teams to be more selective in the work they outsource, and give them more leverage to structure their fees under alternative fee arrangements for work sent to outside counsel.
Bloomberg Law AI Assistant transforms legal research with interactive discussions, jurisdictional filtering, chart comparisons, and instant source verification.
Legal software powered by AI you can trust
With recent AI and machine learning breakthroughs, legal technology software products are starting to incorporate AI to assist with legal matters. The nuances and challenges of AI and machine learning aren’t new to us – in fact, we’ve been testing and building the Bloomberg Law all-in-one legal platform with the most cutting-edge AI technology for more than a decade. With the unmatched speed of AI layered into the world’s top legal intelligence platform, legal professionals can prepare better and faster than ever before.
Want to learn more about how generative AI is transforming the practice of law? Download our report, Adopting AI in Legal Practice: Risks, Rewards, and Realities, to explore how to successfully integrate AI in legal workflows.
Request a demo to see how Bloomberg Law is the only AI-driven platform you need to execute a winning legal strategy.